Data Collection & Preparation
Integrated Pipeline for Data collection, Cleansing and Management
Data is the lifeblood of all Ai/Ml projects and is the foundational part for generating insights. In order to effectively integrate a variety of data sources, organizations need to align the data, transform it and promote the development and adoption of data standards.
We assist Analysts and Data scientists services to collect, cleanse, process and consolidate data for further processing to effectively manage the volume, variety, veracity and velocity of the data. Some key challenges we work on are :-
 Multiple data formats
Multiple data formats
 Data inconsistency
Data inconsistency
 Limited/large access to data
Limited/large access to data
 Lack of data integration infrastructure
Lack of data integration infrastructure
Deduplication and Identity Resolution
We help enterprises discover risks, frauds, and conflicts of interest and develop operational intelligence in their business processes . Typical customers we have worked with have big data related requirements and include enterprises operating in Telecom, financial institutions , insurance, Retail, E commerce verticals.

Master Data Management
We provide Data Management services using internal and third party tools. We use proprietary Ai algorithms that learn patterns from the data itself without handcrafting any rules or algorithms. Our expertise includes building complete solutions for De duplication, Entity resolution and Data Unification by integrating data silos like NoSQL databases, RDBMS, S3, Azure Data lakes etc in different formats – Avro, Parquet, CSV, JSON, XML etc.
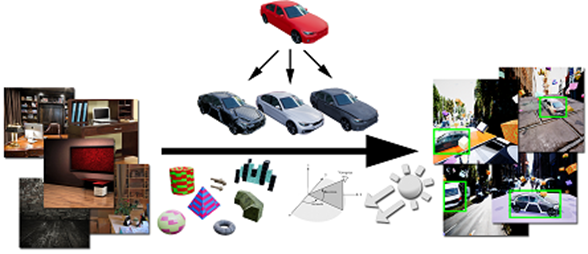
Synthetic Training data
We use algorithms and generative models to artificially create data sets for training, validation and testing for a diverse set of sensors. Synthetic data are typically useful when it is time consuming and expensive to generate privacy f constraint free, regulatory compliant real data. We can help create a golden data set from a base line reference (imputation model) or create a baseline ourselves and then build the reference data per custom use case scenarios.