Feature Preparation
Training data pipeline with Data Annotation
Choosing informative, discriminating and independent features area a crucial step for building effective algorithms for pattern recognition, classification and regression.
Feature engineering enables the algorithms/ model to understand the data using domain knowledge in the same way as humans do and could be the secret a to making your Algorithms work phenomenally well. We work with Data analysts and Data scientists in development of powerful features that can produce results efficiently, effectively, and consistently engineer better models. Some key activities we work on include-
 Data Augmentation
Data Augmentation
 Feature selection
Feature selection
 Construction
Construction
 Annotation
Annotation
Annotation
We provide annotation services as a combination of self service, human in the loop and manual to handle diverse use cases and work loads. We have demonstrable expertise and experience of shrinking manual processes yet maintaining a high degree of accuracy. Annotation techniques supported include-


2D bounding box- Determine object localization and classification using rectangular boxes .


Cuboidal bounding box- creating cuboids to obtain a 3D representation of the object, allowing systems to distinguish features like volume, position and distance in a 3D space.


Polygons/ Irregular contour shapes- Using complex polygons to define the shape and location of the object in a precise manner.


Semantic segmentation-Classifying each pixel in an image to a pre-defined class wherein each pixel bears a semantic meaning.


Key point / Landmark annotation- detect small objects and shape variations by creating dots across the image.


Polylines- Using lines and splines to detect and recognize lanes.


Video Annotation- Adding Metadata to unannotated video – detect and classify objects to train Ai models.

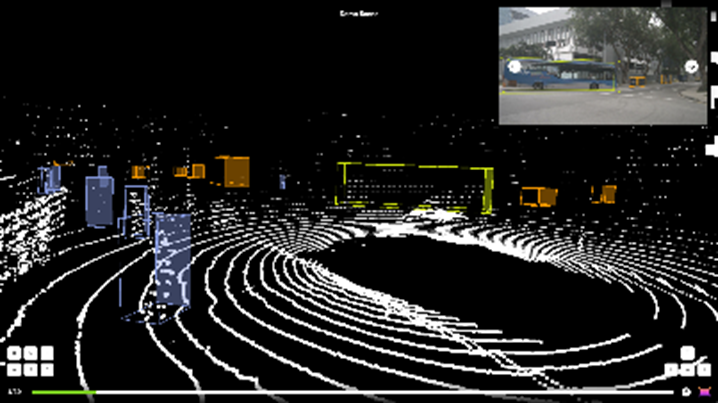
Autonomous driving- labeling for self driving vehicles including- Lidar, Radar and Camera sensor data-